随着做程序员的时间越来越久,经历过快速跑业务堆需求,经历过做基础做框架搞平台搞提效,越来越觉得代码的可维护性不是个非好即坏的状态。有复杂的各种输入影响代码的最终状态(指可维护性、后略),代码的状态又进一步影响项目,最终在当前项目这个整个大的研发系统下达到一定的平衡。这个平衡状态可能不是大家想要的状态,但是一般这种平衡却其实是较符合项目现状的稳定状态。如果没有较大的外力来影响系统,这个平衡是比较难打破和改变的。只要不出现项目无法维护的情况,那它有可能会一直持续下去。
今天我想就这一些状态、影响和平衡,过去这些年产生的技术、框架解决的一些问题等,聊聊我的思考。
给我100个C++之父代码就会好?
之前我常常觉得项目的代码越来越烂了,那一定是团队里的人太菜了。如果给我十几个牛x的程序员,甚至再给兄弟组和上下游都安排上xxx之父级别的程序员,项目代码里的各种问题一定都会迎刃而解。但是这是真相吗?
首先现实的问题就是,招不来那么多牛x的人。而且牛x的人大部分也是从菜鸡成长起来的,为什么我们的环境就培养不出这样的大神呢?
其次很重要的一点就是,我们维护的项目不是在车间里可以反复停机调试的机器,然后出厂就是最终产品。它更像是在高速运行的车,我们要边跑边升级。最早的时候它可能是自行车,用户少功能简单,偶尔还可以停下来修一修。到后面逐渐变成跑高速的汽车,我们要在它疾驰的途中不停的替换零件,在不停止运行的前提下逐渐将它升级成高铁动车。这是一件很难的事,能维持汽车不减速就已经很难了,至少现在的汽车工业还做不到不停车就能换车轮🐶。
还有一个难点,我们所写的代码不光是面向现在的需求,还要面向未来的扩展、升级。哪怕我们神机妙算如诸葛丞相,能预料到1-2年后的需求并预留好扩展口,也很难应对3-5年一轮技术革命后的新需求。更何况现在技术发展这么快,GPT都半年升个大版本,1年后的需求会是什么样就基本已经无法预测了。
总体来说,完美状态的项目只存在于梦里。在现实里开发项目,就只能尽可能努力,让项目的平衡点尽可能倾向对自己有利的一边。更加实际的可做项是:立刻去做,先行动起来。每天思考思考怎么样可以优化可维护性(学习和思考),每天把能看到的可优化点一点点做掉(行动)。遇到困难,觉得都怪队友菜是甩锅,觉得反正也好不了就摆烂是逃避,都没法切实的真正对自己产生好处。所以不如直接去做,做的途中自己有收获就不亏,受到认可项目也成功那就是双赢,心态放好才能笑到最后。
靠框架和标准解决分工问题
软件开发有一个很大的难点,就是需求的分工和代码的分工很难完全匹配一一对应。举个例子:
需求是给IM软件加一个会议邀请功能。参与的研发有日历团队、会议室管理团队、音视频会议团队、聊天功能团队等,这是一个需求对应多个功能模块的情况,团队一多就需要额外的沟通和对接成本。细化到单个模块内的研发工作一样是很复杂的,PRD里一小段就可以说清楚的会邀卡片样式逻辑,研发至少需要了解聊天模块怎么添加新消息类型、对应数据库模型以及和服务端的同步逻辑、UI交互实现、对其它功能的影响等。如果这些内容交给不同的人负责,那么沟通成本会上升;如果这需求交给一个研发负责,那么他的学习成本很高,需要很久才能成为熟手。
最终在不同团队和单个团队内都会产生矛盾,核心原因就在于需求是以完整连贯的一系列UI和交互为单位,但是代码模块是按照功能类型进行划分的,从划分模式和划分粒度来看都没有办法做到两者的同步。
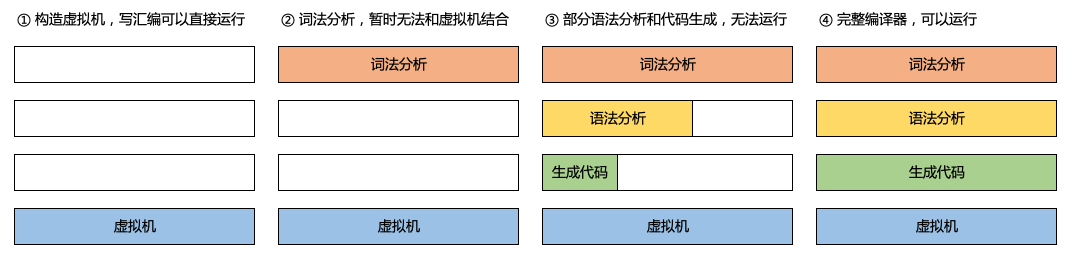
既然现实是这样的,我们该怎么办?其实研发的工作不光是翻译和实现需求,还要在过程中进行总结梳理、规划和抽象。直接低质量直译的结果就类似于把「Cat’s out of the bag.」翻译成「猫从包里出来了」一样。而想建成一个准工业流水线,不光是要把模块划分得足够独立、职责清晰,还得大家的划分逻辑比较一致,这样可以减少学习和沟通的成本。所以诞生了Coding Style和应用框架这样的标准,各中大型app团队也都在持续关注组件化和标准化的相关技术。拿iOS这些年的常见应用框架举例:
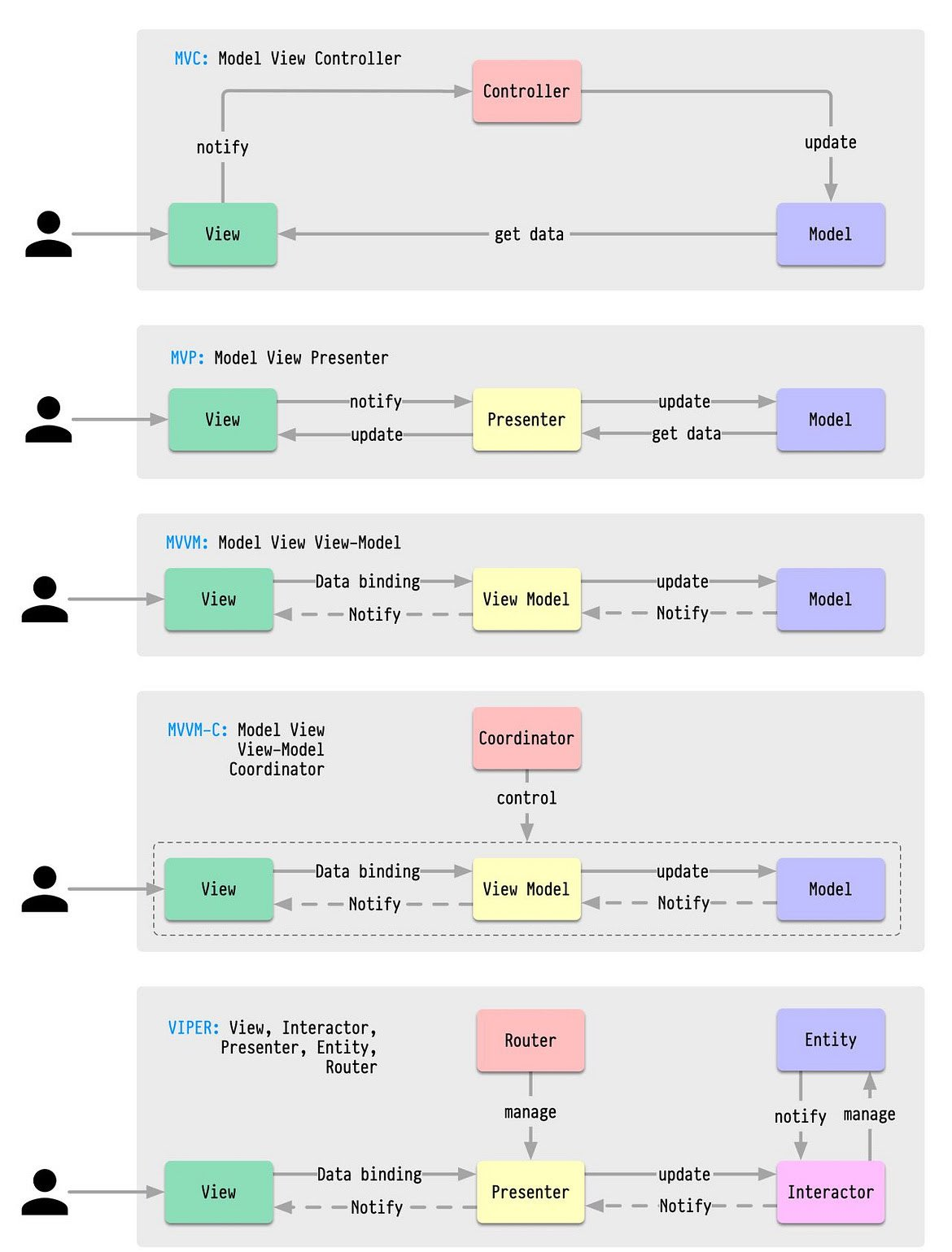
图片来自原文
- MVC阶段最被人诟病的就是超大Controller,一个类大几千行。虽然大多时候文件行数多了逻辑就会乱,但其实不是行数多了就一定会乱。MVC时代没有什么标准,埋点该写在哪,请求结束该怎么刷新界面这些都没有定论,每个人都有自己的想法,东补一块西补一块。所以代码乱的核心原因还是一起修改文件的人多了,而且大家还没有统一的标准。
- 前辈们发现有些逻辑是比较通用的,比如大部分页面都有请求、组装和持久化数据这一类逻辑,那么定个标准把这些逻辑统一抽出来写成单独的类或者扩展,以后大家都知道请求和数据相关的内容去这里处理。抽出来的一些逻辑就渐渐变成了Presenter。
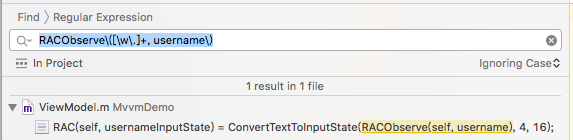
- 我觉得MVVM的核心贡献不是ViewModel,而是DataBinding。在此之前数据和UI组件的绑定方法是多样和混乱的,以用户名输入框为例,有人这么写:
1 | var userName: String? |
这是纯过程式的写法,写入读取的地方分散在文件各处,多了以后很容易漏改。有些封装意识的同学可能会尝试用get、set方法把变量读写和数据库绑定一下,再做个和textView.text的自动联动。但是有了DataBinding之后,写法将被统一为类似这样:
1 | userName.bind(textView.text) |
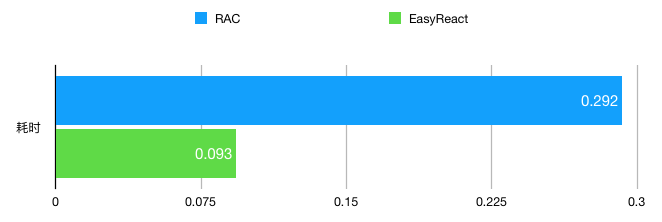
这样的好处是写法逐渐标准化,并且相关逻辑的代码集中在了一起,使得代码更偏向人类可阅读的状态。IGList的出现也把列表的刷新逻辑逐渐标准化了,达到的是类似的效果,顺便还提升了性能,那它不火谁火?唯一的坏处是,从MVVM+RAC开始,代码的学习和调试难度变高了,如果有不懂原理的人瞎写代码容易出现极难排查的问题🐶。
- MVVM解决了单个页面的分工标准问题,跨页面问题该如何解决呢?A页面要跳转到B,就一定要依赖B并负责创建B的实例,以后有改动时该A的研发来改还是B的研发呢?B页面如果需要知道自己从A跳转而来,比如一些埋点需求的
fromPage参数,又该怎么做耦合才能更小呢?没有约束的话又会变成百花齐放的状态,慢慢的我们发现需要一个跨页面调度管理类,因此诞生了叫做Coordinator或者Navigator的工具类,借助router或者依赖注入等方法做到数据传递和解耦。于是我们又得到一个新的标准,页面跳转或者跨页面传递参数应该用Coordinator。 - 随着ViewModel本身都变得越来越臃肿,我们又需要为ViewModel制定一些新的标准并做一些新的拆分,抽出一些更细粒度的公共Context/Service/Manager/Helper。比如最早我们说的埋点可以定义一个TrackHelper,请求可以定义一个RequestService,那么以后大家找请求、埋埋点就立刻知道该去哪儿找代码了。抽出来的这些类成为VIPER的Interactor,ViewModel变成VIPER的Presenter。
总体来说,框架发展的过程中,出现了一些简化代码梳理代码的工具,也树立了代码该怎么写、该写哪儿的标准,很大程度上帮助我们把代码拆成更小的粒度,方便我们快速定位到要修改的代码,也方便我们应对各种需求的变化。反过来说,如果我们不知道代码该写哪儿,而且还多处出现类似代码,那么是时候思考一下要不要搞新的工具和标准化了。不过这些都要结合团队的实际状况来看,没有工具支持或者标准尚未立清楚的情况下就开始强推新框架,一般会适得其反。
什么样的代码是好代码?
框架、组件化和标准化的推进,使得我们按照框架标准去写代码,就会得到相对易理解易维护的代码。直白点说,这些方案是为了限制并牺牲大家的一部分自由,以此来提高代码健康度的下限。但是有些逻辑是在标准的定义范围之外的,又或者说我们想进一步提高代码健康度的上限,这时候该怎么判断我们写的代码是好还是坏呢?
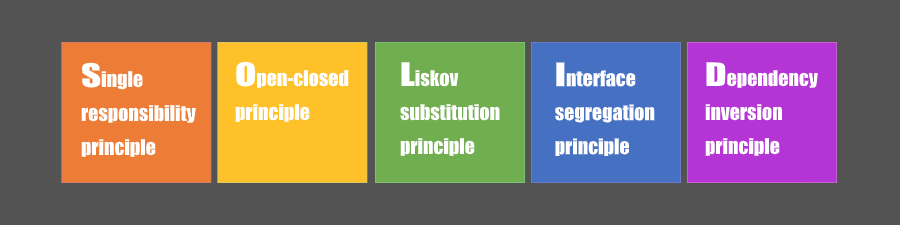
生活里的例子比较好理解,比如手机的蓝牙坏了应该还能用才对,喇叭和屏幕之间也应该相互独立不影响,大家见多了也就知道怎么样是合理的了。有些人对代码有良好的感觉,看到代码就能靠直觉判断代码的好坏,跟我们判断生活场景一样简单。但如果没有这种感觉,是不是就没有做程序员的天赋?我可以肯定的说绝对不是,至少程序员是可以靠努力提高实力的,一些简单的面向对象开发原则就能帮助我们判断代码的好坏。
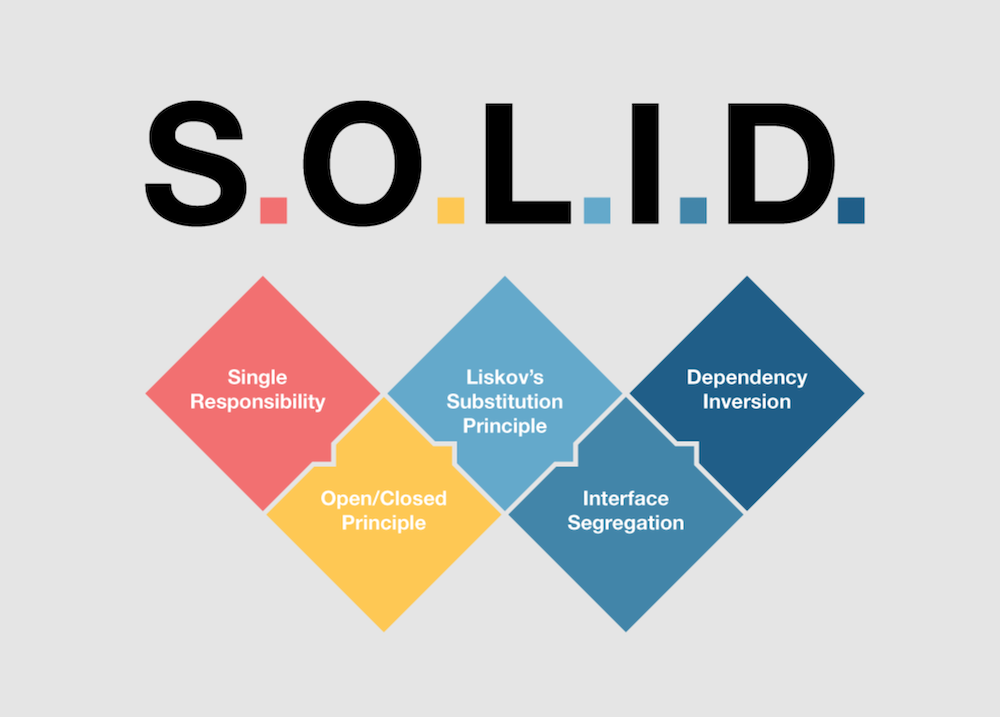
图片来自原文
S – Single Responsibility Principle 单一职责原则
单一职责就是类似上一节里说的内容,一个类的功能越单一越明确越好。手机的喇叭应该只负责播放声音,屏幕应该只负责显示画面,相互独立没有耦合,总不能调节音量影响了屏幕亮度。iOS开发里最容易不满足单一职责原则的类就是ViewController了,不知道该写到哪儿的代码都被扔到了这个类里,我们可以做的就是尽可能只在Controller里写一些UI布局和组织其他模块的代码,让它的功能逐渐单一化。
L – Liskov Substitution Principle 里氏替换原则
里氏替换就是指子类可以无缝替换父类,而不造成系统的异常。要实现这个原则有些小tips:
- 子类的输入条件要比父类宽松,子类的输出内容要比父类严格
- 子类可以添加扩展父类的功能,但是不能删除修改父类的功能
- 不可以有直接判断类型来进行不同操作的逻辑
比如最常见的不满足里氏替换原则的继承关系:
1 | class Rectangle { |
比如现在有父类为鸟,基本属性有脚有翅膀。子类为鸽子,有脚有翅膀,而且会飞,这就是一个正常的满足里氏替换原则的设计。但是如果在父类直接定义鸟类会飞,身为子类的企鹅就傻眼了(子类删除了父类功能)。合理的做法是定义一个Flyable扩展协议,让会飞的鸟实现这个扩展协议即可。
又比如现在有父类汽车,子类为传统油车和新能源车,这个设计是没毛病的。但是又实现了一个所用能源方法如下,要是以后万一出来原力汽车咋办?
1 | if 汽车 is 新能源车 { |
当然,针对里氏替换原则所指向的继承方案,我个人更推荐组合而不是继承,从根本上减少不合理继承带来的困扰。
I – Interface Segregation Principle 接口隔离原则
用简单直白一点的话说,接口设计喜欢小而独立,不喜欢大而全。大家有没有想过UITableView的delegate和dataSource为什么要分开?再用上面的鸟类来说,不适合在基类直接定义isFlyable、isSwimmable,也不适合直接定义FlyableAndSwimmable这样的复合接口,而适合分开定义Flyable、Swimmable两个接口,因为他们本来就应该是分开的,不应该相互关联并强制使用者去实现他们不需要的功能。但是反观我们在开发的过程中,为了快速方便的实现功能,喜欢给一个类增加超多的方法和属性而不进行分类,从而形成破窗效应让代码状态持续恶化。
D – Dependency Inversion Principle 依赖倒置原则
依赖倒置不光是个原则,也是个实现优秀设计的核心方法。上文提到的组合优于继承,解耦合并实现接口隔离,其实都是能用依赖倒置的方法实现的。依赖倒置的核心就是模块之间不应该依赖具体的实现(或者说实例),而应该依赖抽象(接口)。
比如说我现在有一个电脑主机和一个显示器一个音箱,想要展示内容播放声音该怎么写,粗糙的写法可能是这样:
1 | class Computer { |
现在我们的显示器是HDMI的,也支持播放声音,我们想从显示器播放声音,粗糙的改一下:
1 | class Screen { |
是不是总感觉不太舒服,好像写了些不该写的代码,而且以后有更多的播放设备该怎么办,每一个里面都实现一遍play(sound)函数并增加变量去控制吗?所以办法就是我们不要去依赖具体的实例以及实现,我们应该去依赖接口:
1 | class Screen: DisplayDeviceProtocol, AudioDeviceProtocol {} |
以后有再多的音频设备,只要它实现了AudioDeviceProtocol,我们都可以直接扔给Computer类去用来播放声音,而不用对Computer类进行修改,这就是依赖倒置原则带来的好处。
O – Open Closed Principle 开闭原则
开闭原则的要求是对扩展开放、对修改封闭。比如我们可以给手机套个手机壳插个充电宝,但是不能随便翘开手机换主板。为什么把这一条放到最后来说呢?因为能做到前面的各个原则,写出来的代码基本上就符合开闭原则了。前面举的电脑的例子里,如果没有用上依赖倒置,那么我们只能频繁修改Computer类,没办法轻易扩展新的音频设备,这就是对修改开放、对扩展封闭的一个反例。又比如前面汽车的例子里,我们增加新类型的汽车就一定要修改其能源模块的代码,这时候就应该把能源抽象成独立的接口了。
取得平衡
完全遵守这些规则,代码的设计难度和实现时长一定会变长,在项目进度极度紧张的时候会很难执行。但是相信一句话叫做磨刀不误砍柴工,对于需要长期迭代的工程来说这些都是值得的,想办法让你的老板和上游也了解并相信这一点。还是前面那句话,至少要尽力争取,让代码状态的天平尽可能向自己倾斜,摆烂只会让自己的工作状态越来越糟。
又或者说,就算这个项目做不下去了,自己也要学到些东西好在下一个项目大展拳脚吧🐶。
结语
写了一堆,总结起来也就是:
- 代码很少有绝对的好或烂,大多是在一个中间的平衡状态,我们要持续努力让它更好,而不是破罐破摔等待毁灭
- 结合项目现状,持续的进行标准化、组件化相关工作,引入适合团队的新框架,可以保住代码状态的下限
- 了解怎么实现好代码,在遇到设计难题的时候用套公式的方法都可以提高设计水平,剩下来的就是熟能生巧了,持续提高自己的上限
祝大家都能有强大的实力和容易实现的需求,也祝大家新年快乐🎉
]]>